Neural Magic’s ability to optimize the resource efficiency of open source LLMs—including Llama, Mistral, Gemma, Granite and Qwen—has clear benefits for organizations looking to leverage Red Hat’s hybrid cloud product portfolio. By employing advanced mathematical operations and algorithms to reduce the hardware footprint of these LLMs, Neural Magic helps businesses deploy more LLM workloads without having to purchase more GPUs, TPUs, IPUs, RDUs, etc. This improved efficiency could become a compelling factor when choosing Red Hat’s hybrid cloud application stack over competing platforms.

In addition to broad open source LLM support, Neural Magic has been the top commercial contributor to the vLLM open-source inferencing server, originally started at University of California, Berkeley. This community project focuses on simplifying the deployment and lifecycle management of LLMs, while at the same time optimizing performance and resource efficiency. This lets users run already optimized turnkey LLMs from the HuggingFace Hub. More experienced users with more specific requirements, such as advanced domain adaptation or integrating proprietary data sets, can fine-tune the base models for specialized use cases (e.g., medical text analysis or financial forecasting). Neural Magic is taking an active role in supporting vLLM inferencing across heterogeneous accelerators, including Nvidia, AMD, Google TPUs, and Intel, bringing choice and optionality to inference deployments
Key to Neural Magic’s approach is the incorporation of sparsity and quantization into vLLM, an open source inferencing server. Sparsity applies a number of mathematical principles (weight pruning, sparse activation, low-rank factorization, and regularization techniques) to only use the parts of the AI model that are critical for accurate inferencing. Not only do sparse models require less memory, they can also move the data closer together (locality of reference) to ensure more efficient use of processor cache, further accelerating inference speed.
Quantization reduces the resolution (number of dimensions) of the input weights of the model, enabling more efficient computation and reduced memory usage while maintaining performance. Combined, sparsity and quantization reduce memory usage and computational demands, enhancing resource efficiency for LLMs in real-life use cases.
Open Source
Neural Magic’s emphasis on open-source software and AI models aligns closely with Red Hat’s own commitment. By contributing to the rapidly growing vLLM open source project, Neural Magic not only showcases its ability to optimize LLMs for performance and resource consumption, but also benefits from community feedback and collaboration. In addition to 14 regular contributors from Neural Magic, vLLM draws support from University of California, Berkeley and, interestingly enough, from IBM/Red Hat.
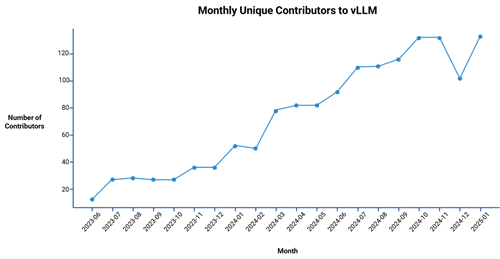
Open source is central to Neural Magic’s strategy: It enables developers, researchers, and enterprises to freely access and modify its tools, fueling rapid innovation in areas such as model integration, production monitoring (e.g., Prometheus metrics and Grafana dashboards), multi-accelerator support for scalable inference, Kubernetes integration, and advanced mathematical techniques for performance optimization. Meanwhile, Red Hat, long synonymous with enterprise open source, expands its AI footprint by incorporating Neural Magic’s open source projects into its broader hybrid cloud ecosystem. This alignment underlines Red Hat’s commitment to delivering transparent, scalable, community-driven solutions—empowering customers to adopt AI more easily and with full visibility into the underlying technology stack.
All of this reinforces the argument that Red Hat’s hybrid cloud application platform, combined with Neural Magic’s optimizations, can deliver both cost and performance advantages for organizations looking to maximize LLM potential in their hybrid cloud environments.